Benchmark#
The included bench.mjs script evaluates loading performance for all
supported formats. It loads the file 11 times and reports the time for
the last 10 (ignoring the first cold-start / disk cache run).
Running the Benchmark#
node bench.mjs dpsv.trx
Results#
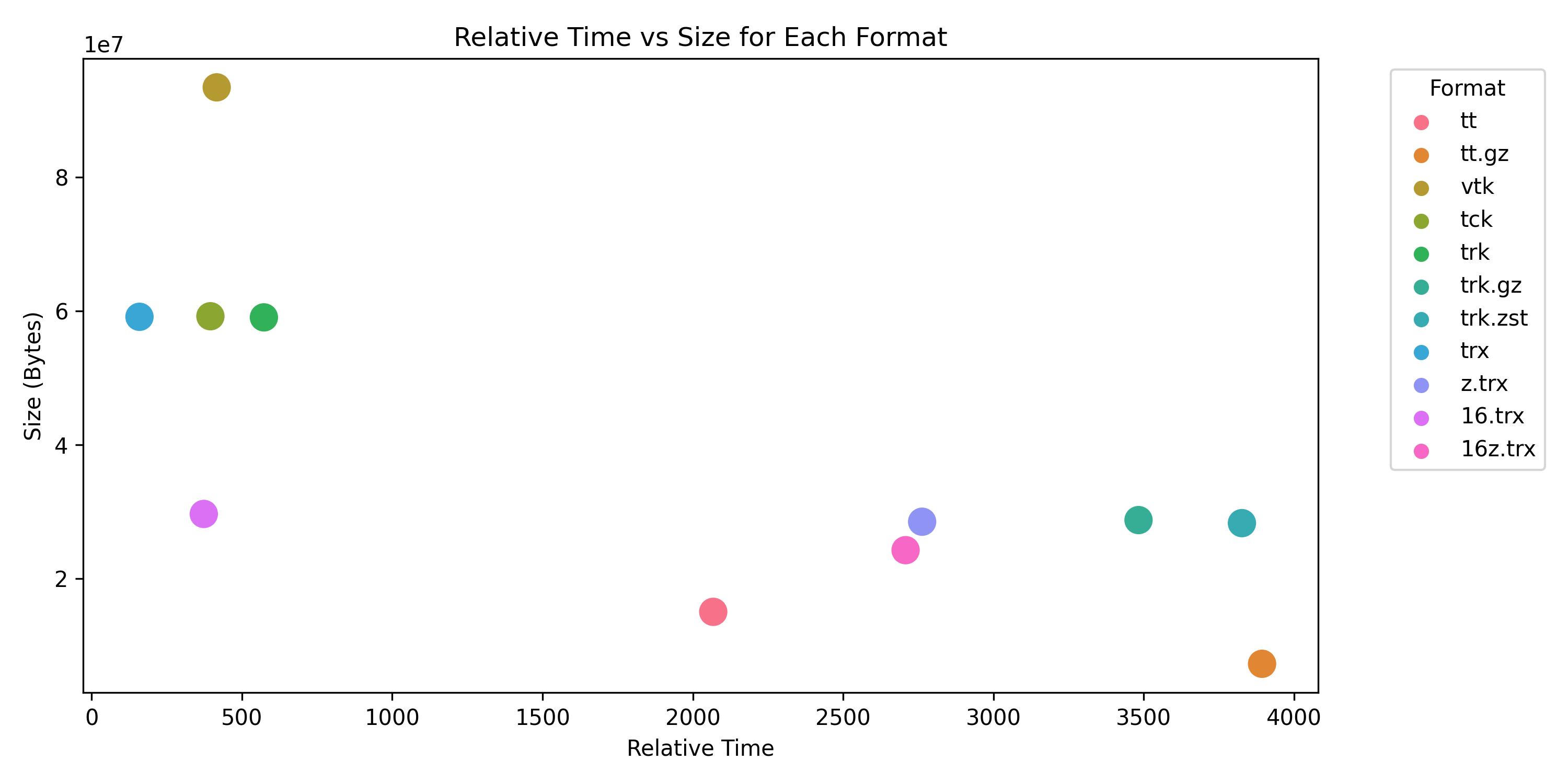
The graph below shows load time for the left inferior fronto-occipital fasciculus (IFOF) from the HCP1065 Population-Averaged Tractography Atlas (Yeh, 2022) — 21,209 streamlines and 4,915,166 vertices.
Formats were generated with tff_convert_tractogram.py. Benchmark run on a MacBook with an M2 Pro CPU, loading from local SSD.
Format Summary#
Format |
Extension |
Notes |
|---|---|---|
tt |
|
DSI Studio — very compact; 1/32 voxel precision (slightly lossy) |
tt.gz |
|
Gzip-compressed DSI Studio |
vtk |
|
VTK legacy (DiPy OFFSETS, |
tck |
|
MRtrix format |
trk |
|
TrackVis format |
trk.gz |
|
Gzip-compressed TrackVis |
trk.zst |
|
Zstandard-compressed TrackVis |
trx |
|
Uncompressed TRX |
z.trx |
|
Zip-compressed TRX |
16.trx |
|
TRX with float16 positions |
16z.trx |
|
Zip-compressed TRX with float16 positions |
Note: Native zstd decompression is very fast, but the JavaScript decompressor (
fzstd) is relatively slower than native implementations.